The purpose of this section is to give a brief description of the lifting scheme. A more detailed information can be found in [4,5].
Constructing wavelets using lifting consists of three simple phases.
The first step or Lazy wavelet splits the data
![]() into two subsets, even and odd.
The new data sequence is given by
into two subsets, even and odd.
The new data sequence is given by
The second step calculates the wavelet coefficients (high pass) as the
failure to predict the odd set based on the even:
For our practical purpose we use the cubic interpolation scheme, using two neighboring values on either side and define the (unique) cubic polynomial which interpolates those four values. This interpolation scheme allows us to easily accommodate interval boundaries for finite sequences, such as in our case. For the cubic construction described above, we can take 1 sample on the left and 3 on the right at the left boundary of an interval. The cases are similar if we are at the right boundary.
Finally, the third step updates the even set using the wavelet
coefficients (low pass).
The idea is to find a better
![]() so that a certain scalar
quantity
so that a certain scalar
quantity ![]() , i.e. mean, is preserved, or
, i.e. mean, is preserved, or
The three stages of lifting described by (1), (2) and
(3) are combined and iterated to generate the fast lifted wavelet
transform algorithm:
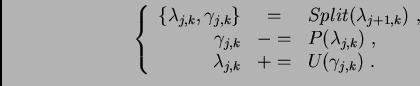 |
We can now illustrate one of the nice properties of lifting: once we have
the forward transform, we can immediately derive the inverse.
We just have to reverse the operations and toggle ![]() and
and ![]() .
This idea leads to the following inverse transform:
.
This idea leads to the following inverse transform:
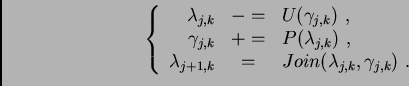 |
An example with using the filter coefficients ![]() (at the predict
stage) and lifting coefficients
(at the predict
stage) and lifting coefficients ![]() (at the update stage) already
shows how the lifting scheme can speed up the implementation of the wavelet
transform.
Classically, the
(at the update stage) already
shows how the lifting scheme can speed up the implementation of the wavelet
transform.
Classically, the
![]() coefficients are found as the
convolution of the
coefficients are found as the
convolution of the
![]() coefficients with the filter
coefficients with the filter
![]() .
This step would take 6 operations per coefficient while lifting only needs 3.
.
This step would take 6 operations per coefficient while lifting only needs 3.
The total number of iterations in this simplest case is
![]() , where
, where ![]() is the signal length.
In the case we use
is the signal length.
In the case we use
![$ \displaystyle n=\left[\log_2\left(\frac{L-1}{3}\right)\right]$](img24.png) .
It can be seen from this equation that the size of the signal does not matter,
i. e., signals do not necessarily have to have dyadic dimensions.
The interpolating subdivision guarantees a correct treatment of the boundaries
for every case.
.
It can be seen from this equation that the size of the signal does not matter,
i. e., signals do not necessarily have to have dyadic dimensions.
The interpolating subdivision guarantees a correct treatment of the boundaries
for every case.